

TCP Window Size
What is TCP window size and why does it matter? Unlike UDP, which is a best effort protocol, TCP is considered a reliable protocol. Reliable because it guarantees the data transmission. It does this by having the receiver send acknowledgment packets back to the sender. But how often? Without getting too much into TCP algorithms, TCP has a queue that is used for retransmitting packets. This wouldn't scale very well if every packet had to be acknowledged as the sender has to wait for an acknowledgment before clearing the queue. This is where the window size comes into play. The window size is basically the amount of data the sender will transmit before it waits for an acknowledgment. The key word here is wait. Other complexities ignored, the sender will not move on until the acknowledgment comes back. You can see how forcing acknowledgments too often can cause the data rate to slow. There is a simple equation for the theoretical maximum transfer rate for a given window size and delay.
Window_Size (Bytes) * 8 bits / RTT_in_Seconds = Transfer_Rate (bps)
This is the maximum transfer rate as the line rate approaches infinity. Since an acknowledgment packet is usually pretty low in size compared to the real line rate, the actual transfer rate is pretty close to the theoretical rate. In other words, we don’t have to include the time it takes to place the acknowledgments “on the wire” in the equation because it won’t change the result by a significant amount.
I’ve setup two VMs connected directly to each other and put a cloud in the middle to pretend they are far apart.

We will run some iperf tests with different window (buffer) sizes and delays to see how the transfer rate is impacted. We will simulate network delay by tweaking a setting on one of the VMs. It doesn’t matter which one as a delay on either would result in the round trip time increasing.
This actually holds true in real-life; we have no way of knowing the speed of light isn’t double in one direction and instantaneous in the opposite direction. In fact, I’ve tested this theory on a Skype call with my dad. Adding a delay to my PC sending data to my dad’s translates to a delay in the RTT of the entire call. I appeared delayed to my dad and he appeared delayed to me. It didn’t matter that his voice transmitted to me in a few milliseconds, he still appeared to respond several seconds after me. We could have had atomic clocks synced any which way, given that skype call alone, we would have had no way of knowing the delay wasn’t symmetrical.
First, I want to turn off window scaling so it’s not screwing up my tests. I’m doing this on the VM that will be the server and you’ll see why later.
ubuntu@receiver:~$ sudo su
[sudo] password for ubuntu:
root@receiver:/home/ubuntu# echo 0 > /proc/sys/net/ipv4/tcp_window_scaling
root@receiver:/home/ubuntu#
Let’s see what the existing delay is on the network.
ubuntu@sender:~$ ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.990 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.950 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.929 ms
64 bytes from 10.0.0.2: icmp_seq=4 ttl=64 time=0.881 ms
^C
--- 10.0.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 0.881/0.937/0.990/0.049 ms
ubuntu@sender:~$
Iperf result:
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 1.17 GBytes 1.01 Gbits/sec 0 sender
[ 4] 0.00-10.00 sec 1.17 GBytes 1.01 Gbits/sec receiver
Now, let’s add a delay. We are going to use a linux tool called tc. It is a really cool tool and I use it a lot for testing transfer behavior in different scenarios. A quick tab to see some options:
ubuntu@sender:~$ sudo tc qdisc add dev ens3 root netem
corrupt distribution ecn rate
delay duplicate loss reorder
We’ll use delay.
sudo tc qdisc add dev ens3 root netem delay 50ms
And that simply, we now have a delay of 50 milliseconds in our network. Just replace “add” with “change” for the above command to change the delay to something else. Use “delete” or change the delay to 0ms to remove the delay.
ubuntu@sender:~$ ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=50.7 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=51.2 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=51.3 ms
^C
--- 10.0.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004ms
rtt min/avg/max/mdev = 50.704/51.111/51.336/0.288 ms
ubuntu@sender:~$
Since the tcp window can’t scale
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 12.6 MBytes 10.6 Mbits/sec 0 sender
[ 4] 0.00-10.00 sec 11.9 MBytes 10.0 Mbits/sec receiver
Let's look at the wireshark. You'll see the initiator sent a syn with window scaling but the other side doesn't support it so no window scaling was negotiated.


In the wireshark capture, we can see a window size of 64240 bytes. Throwing that into our formula from above,
64240 * 8 / 0.051 = 10,076,862.75 or 10Mbps
It’s easy to see how devastating disabling window scaling can be on TCP transfers across a WAN as the window size can’t go past 65535. Let’s try a window size of 30k and a delay of 40ms. We should expect 30k * 8 / 0.041 = 5,854kbps.
ubuntu@sender:~$ sudo tc qdisc change dev ens3 root netem delay 40ms
[sudo] password for ubuntu:
ubuntu@sender:~$ ping 10.0.0.2 -c 1
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=40.8 ms
--- 10.0.0.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 40.863/40.863/40.863/0.000 ms
ubuntu@sender:~$ iperf3 -c 10.0.0.2 -w 30k
Connecting to host 10.0.0.2, port 5201
[ 4] local 10.0.0.1 port 36944 connected to 10.0.0.2 port 5201
[ ID] Interval Transfer Bandwidth Retr Cwnd
[ 4] 0.00-1.00 sec 672 KBytes 5.50 Mbits/sec 0 82.0 KBytes
[ 4] 1.00-2.00 sec 675 KBytes 5.53 Mbits/sec 0 82.0 KBytes
[ 4] 2.00-3.00 sec 679 KBytes 5.56 Mbits/sec 0 82.0 KBytes
[ 4] 3.00-4.00 sec 707 KBytes 5.79 Mbits/sec 0 82.0 KBytes
[ 4] 4.00-5.00 sec 679 KBytes 5.56 Mbits/sec 0 82.0 KBytes
[ 4] 5.00-6.00 sec 679 KBytes 5.56 Mbits/sec 0 82.0 KBytes
[ 4] 6.00-7.00 sec 707 KBytes 5.79 Mbits/sec 0 82.0 KBytes
[ 4] 7.00-8.00 sec 679 KBytes 5.56 Mbits/sec 0 82.0 KBytes
[ 4] 8.00-9.00 sec 677 KBytes 5.55 Mbits/sec 0 82.0 KBytes
[ 4] 9.00-10.00 sec 679 KBytes 5.56 Mbits/sec 0 82.0 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 6.67 MBytes 5.60 Mbits/sec 0 sender
[ 4] 0.00-10.00 sec 6.64 MBytes 5.57 Mbits/sec receiver
iperf Done.
ubuntu@sender:~$

30 * 1024 is 30720 but the MSS is 1460 so the window size, being a multiple of the MSS, will be 30660.
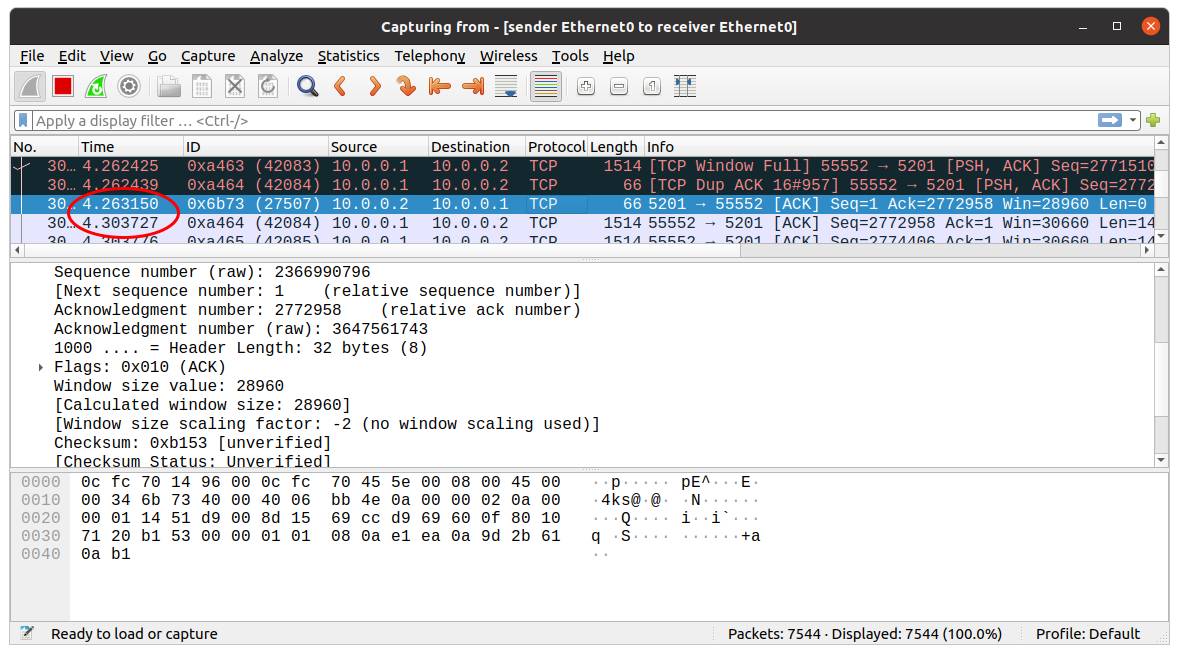
Just to bring home the proof that TCP will wait for the acknowledgment before continuing, below you will see a 40 millisecond delay from when the receiver sends the ack to when the next window of data starts coming in.
Lastly, I want to bring packet loss into the mix. Let’s turn window scaling back on; it won’t be able to scale up much anyway.
ubuntu@receiver:~$ sudo su
[sudo] password for ubuntu:
root@receiver:/home/ubuntu# echo 1 > /proc/sys/net/ipv4/tcp_window_scaling
root@receiver:/home/ubuntu# exit
exit
ubuntu@receiver:~$ iperf3 -s
-----------------------------------------------------------
Server listening on 5201
-----------------------------------------------------------
So, why not just have the largest window size possible? The problem arises when the traffic hits congestion, interface limits, QOS, machine resource restrictions, etc. The sender is going to have a bad day when a duplicate acknowledgment comes back for a packet that was 100MB ago. This is why the TCP window size is something that can (and very much does) change mid-session. Remember the comment I made earlier about how the window size won't scale up much? The sender is keeping track of the retransmissions and adjusting the window size accordingly. Too many retransmission will cause the traffic to throttle back then slowly increase again.
Window size is a very important and often overlooked aspect of TCP when troubleshooting. It is the reason network engineers ask for a packet capture that includes the TCP handshake. Hopefully, you've learned something new. I know I've learned a thing or two just writing this.